인공지능(AI)의 핵심은 데이터를 기반으로 한 학습입니다. AI가 스스로 문제를 해결하고 더 나은 결정을 내리기 위해서는 학습 과정이 필수적인데요, 이 학습 방법은 크게 지도학습, 비지도학습, 그리고 강화학습으로 나눌 수 있습니다.
지도학습(Supervised Learning)
지도학습은 이미 정답이 있는 데이터를 통해 모델을 학습시키는 방식입니다. 주로 분류와 회귀 문제에 많이 사용됩니다. 예를 들어, 이메일을 '스팸'과 '정상'으로 분류하거나, 주식 가격을 예측할 때 지도학습을 활용할 수 있습니다. 지도학습의 장점은 학습 데이터에 정답이 포함되어 있어 정확도가 높은 예측 모델을 만들 수 있다는 점입니다.
비지도학습(Unsupervised Learning)
비지도학습은 정답이 없는 데이터를 가지고 패턴을 발견하거나 군집을 형성하는 방법입니다. 대표적인 비지도학습의 예로는 고객 데이터를 기반으로 비슷한 성향의 그룹을 찾는 클러스터링(군집화)이 있습니다. 데이터에 대한 사전 지식이 필요 없기 때문에, 데이터를 탐색하고 새로운 인사이트를 찾는 데 유용합니다.
강화학습(Reinforcement Learning)
강화학습은 주어진 환경 속에서 AI 에이전트가 보상을 최대화하기 위해 행동을 학습하는 방법입니다. 주로 게임 AI나 로봇 제어 분야에서 활용되며, 에이전트는 시행착오를 거치며 최적의 전략을 찾아갑니다. 장기적인 목표를 달성하기 위해 복잡한 의사결정을 해야 하는 문제에 적합한 방법입니다.
| 특징 | 지도학습 | 비지도학습 | 강화학습 |
| 정의 | 입력 데이터와 정답(레이블)이 주어져 모델을 학습시키는 방법 | 레이블 없이 데이터의 구조나 패턴을 찾아내는 방법 | 에이전트가 환경과 상호작용하며 보상을 최대화하는 방향으로 학습하는 방법 |
| 데이터 레이블 | 필요(입력과 정답이 쌍을 이룸) | 불필요(레이블 없이 학습) | 필요 없음(보상 신호를 통해 학습) |
| 학습 목표 | 입력에 대한 정확한 출력 예측 | 데이터의 숨겨진 구조, 군집, 차원 축소 등 | 최적의 행동 전략(Policy) 개발을 통해 장기적인 보상 최대화 |
| 주요 알고리즘 | 선형 회귀, 로지스틱 회귀, 서포트 백터 모신(SVM), 신경망 등 | K-평균, 계층적 군집, PCA, 연관 규칙 학습 등 | Q-러닝, 딥 Q 네트워트(DQN), 정책 경사법(Policy Gradient) 등 |
| 응용 분야 | 이미지 분류, 스팸 이메일 필터링, 의료 진단, 주기 에측 등 | 고객 세분화, 이상 탐지, 시장 바구니 분석, 데이터 시각화 등 | 게임 플레이, 로봇 제어, 자율 주행, 금융 거래 전략 등 |
| 피드백 유형 | 명확한 정답을 통한 지도된 피드백 | 데이터 내의 패턴을 스스로 발견 | 보상 신호를 통한 피드백 |
<각 학습 방법의 요약>
인공지능 학습의 통합적 개념: 머신러닝
이러한 지도학습, 비지도학습, 강화학습은 모두 머신러닝(기계학습)의 범주에 포함됩니다. 머신러닝은 AI가 데이터를 통해 학습하고 스스로 개선해 나가는 핵심 기술이며, 이는 기업의 비즈니스와 일상생활 전반에 걸쳐 중요한 역할을 하고 있습니다.
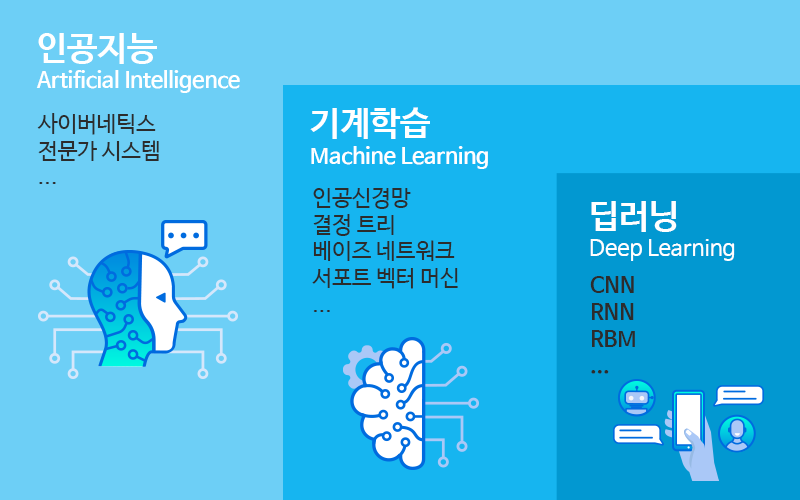
지도학습, 비지도학습, 강화학습에 대한 특징을 알면 주어진 문제에 맞는 최적의 접근법을 선택할 수 있으며, 모델 성능을 더욱 효율적으로 개선할 수 있습니다.
또한, 이 학습 유형들은 데이터 기반 의사결정과 문제 해결 역량을 키우는 밑거름이 됩니다. AI와 데이터 기술의 흐름을 이해하고, 이를 활용해 더 나은 성과를 낼 수 있는 토대를 마련해 보시기 바랍니다.

'서비스 기획 > 이론' 카테고리의 다른 글
| <디자인 씽킹> 창의적 문제 해결을 위한 접근법 (0) | 2024.11.11 |
|---|---|
| AI 모델 구현의 기초 <머신러닝과 딥러닝> 쉽게 이해하기 (1) | 2024.11.08 |
| 흐름과 자원의 시각적 표현 <생키차트> (1) | 2024.10.07 |
| AI 모델 학습 과정을 이해하기 위한 기초 용어 (3) | 2024.09.28 |
| <KPT 회의>로 문제를 해결하고 성과를 극대화하기 (0) | 2024.09.26 |



